
Já faz algum tempo que não coloco nada no blog, acabei me concentrando em outras tecnologias, e o tempo para compartilhar conhecimentos e explicar as coisas ficou curto.
A Imagem_01 traz a visão resumida do projeto que vou comentar aqui, contendo algumas etapas no processo de início de projeto, montar o pipeline de dados e mostra que existe alternativas para o tratamento dos dados, sejam 100% pagas, ou unir recursos já adquiridos com ferramentas Open Source.
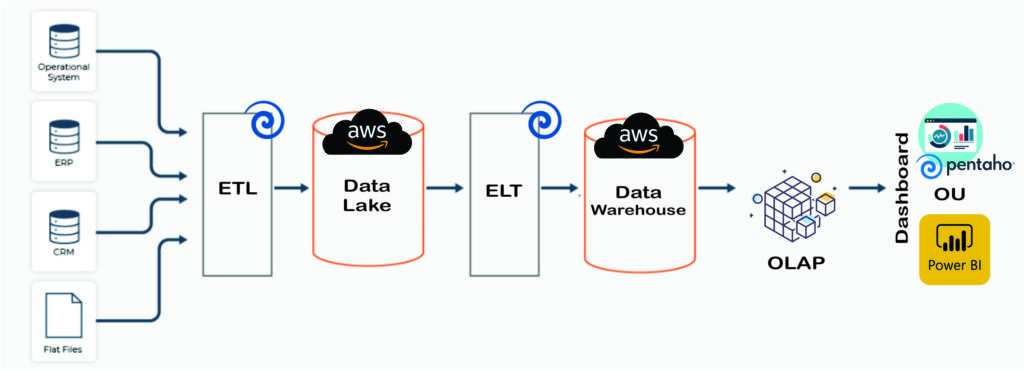 [imagem_01]
[imagem_01]
Antes de iniciar qualquer projeto de dados, é importante considerar estas três coisas:
1. Quem é o público-alvo?
2. Quais são os objetivos do projeto?
3. Como será medido o sucesso?(não confunda com apenas critérios de aceite)
Um complemento a estes pontos iniciais, deve ser considerado que antes de iniciarmos nosso projeto, devemos pensar nos fatores: escopo, tempo e custo.
O primeiro passo é sempre estabelecer um bom relacionamento com o gerente do projeto. Como parceiro-chave, ele ou ela pode lidar com estes três fatores e também precisa estar familiarizado com cada variável e onde ser flexível conforme necessário durante todo o projeto.
 Só uma observação!
Só uma observação!
Ninguém precisa ser Gerente de Projetos (GP) ou exercer a função de GP, mas ter conhecimento prévio do rito inicial, é muito favorável na condução de cada etapa.
Outro ponto importante!
– Elencar as prioridades (com base nas reuniões de planejamento)
– Definir Expectativas de forma Clara (algo bem legal na metodologia Ágil com Scrum é o trabalho de entregas por Scprint’s, acho que dá uma boa visão para o P.O(Proprietário do produto) e o Negócio), ter uma Sprint Review semanal com as partes envolvidas, onde vão acompanhando andamento.
– Documentar, pode ser um grande aliado na revisão do projeto, no momento de aceite de cada etapa/Fase de entrega, costumo fazer isso via Wiki, seja Git ou Azure Devops, consequência disso acaba fortalecendo o foco ou ponto inicial da entrega, versiona consequentemente até as alterações do documento, contribui demais para esclarecer atrasos no Roadmap do projeto.
Agora, vamos falar de um caso prático?!
“ Um cliente me solicitou um relatório financeiro para avaliar os projetos da empresa.
A ferramenta em uso na gestão do projeto é o Redmine, porém quem fez a implantação desta ferramenta não trabalha na empresa já a algum tempo.
A empresa também quer analisar os padrões de preenchimento das tarefas, cronogramas e status. Único problema é recursos, está passando por uma fase de redução de gastos/custos. „
 Lembra das perguntas iniciais???
Lembra das perguntas iniciais???
1. Quem é o público-alvo?
Empresa de consultoria, que presta soluções aos seus clientes, assim como orientações de negócio, quais as áreas envolvidas.
2. Quais são os objetivos do projeto?
Identificar porquê os projetos demoram a serem finalizados, alocar melhor seus recursos, e identificar prejuízos com entregas.
3. Como será medido o sucesso?
Conseguir mostrar onde estão seus recursos profissionais, identificar duração projetos, custos e status.
Vou iniciar os exemplos práticos, estender os pontos teóricos citando os pontos (Planing /Dayling / Review/ Retrospective) acabaria me fazendo ser menos prático.
Estou supondo que o especialista em dados acabou de analisar e absorver a parte inicial completa. Meu objetivo imediato será produzir entregas de cada Sprint que obtiveram evidências de seu progresso e fornecer resultados para mostrar ao cliente.
 O que foi identificado até agora?
O que foi identificado até agora?
-
Digamos que…
— O Redmine foi instalado na instancia do PostgresQL usando o recurso da Amazon RDS.
“Por não ter ninguém com conhecimento sobre a base de dados, através de buscas na internet, localizamos o seguinte modelo de dados. ”
[Imagem_02]
— Agora uma análise exploratória dos dados para responder perguntas iniciais, como : status do projeto, colaboradores, tarefas . . .
Realizado esse processo que pode gerar bastante esforço, podemos montar/planejar uma extração e armazenar na Staging Area de um banco de dados, ou utilizar um Bucket S3 com essa finalidade.
-
Evidenciando um Exemplo
2.1 – Esse foi a primeira evidencia das buscas.
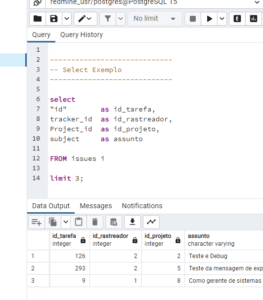
[Imagem_03]
* Ferramenta Pgadmin nativa do PostgresQL
2.2 – Vamos carregar os dados para a Staging
“ Que nesse caso, já usei o Bucket por saber que o resultado é exatamente o que preciso, e tudo está em conformidade ”
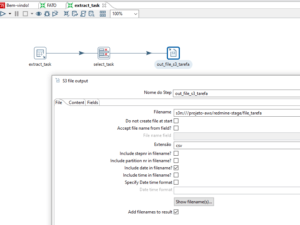
[Imagem_04]
* Ferramenta usada Pentaho Data Integration
3 O cliente enviou evidencias para comparar os dados, validações previas.
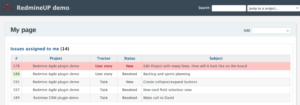
[Imagem_05]
* tela da ferramenta Redmine
Como o objetivo não é granular cada etapa e sim resumir as atividades, vou ser direto no processo do Data Lake, logo abaixo.
O que fazer agora? como gerar um Data Lake?
• Pode ser criado dois S3 Bucket’s um para os Dados Brutos e para Área de Negócio.
• Vou continuar utilizando o ETL do Pentaho, mas poderia ser usado o conjunto AWS Glue/Crawler/Athena.
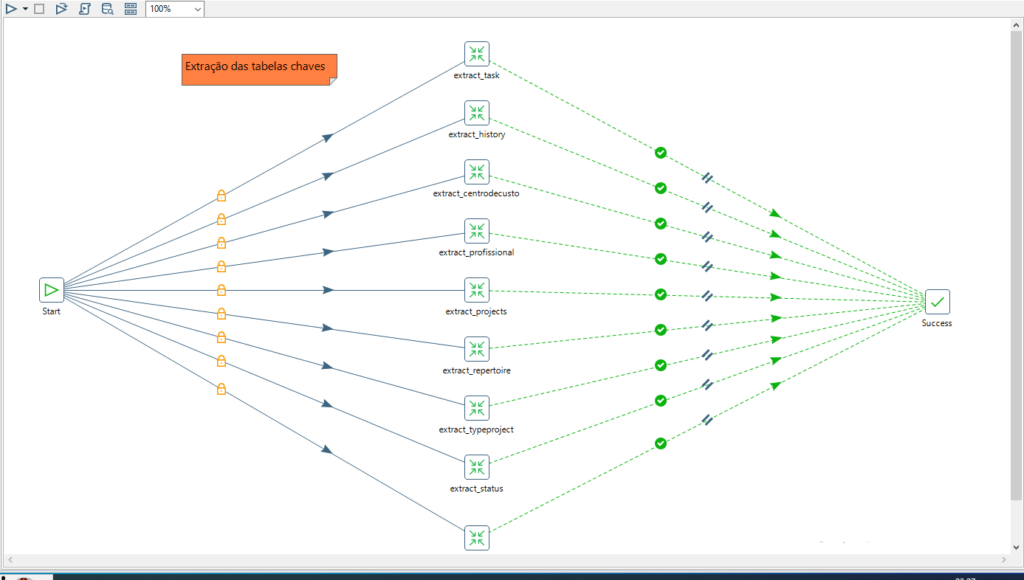
[figura_06]
* Ferramenta usada Pentaho Data Integration direcionando a carga para o bucket Dados Brutos(Raw Data)
• Já o bucket da Área de Negócio (Data Source) pode ser conduzido pelo Crawler e Athena, automaticamente vai atualizando e criando as tabelas, assim como carregando no banco de dados Redshift por exemplo. O pipeline dos dados pode permanecer no Pentaho, claro, que tudo depende do volume de informação.
Os repositórios foram configurados e carregados. Como faz agora? Como fica??
[figura_07]
* Console AWS Bucket, exibindo as pastas de Data Source e Raw Data
Agora é o processo de ELT que pega os dados já carregados, fazendo a extração, e nas transformações já aplicam a regra de negócio.
Certo, eeee ????
Relembro que esse processo, ou fluxo, está seguindo de forma “tranquila” por estarmos alinhados com a necessidade do negócio/cliente e com isso vai ficar um pouco mais fácil.
>> Fermentas para ajudar modelar os dados temos várias, seja o próprio dbeaver, mysql workbench e SQL Power Architect in Database design tool.
A questão de realizar uma modelagem dimensional vem da Melhor compreensão dos processos da empresa, fora melhora forma de fazer manutenção, seja na sua tabela fato ou na própria dimensão o que gera flexibilidade para mudar/Adicionar tabelas e colunas.
Segundo o Ralph Kimball, “As tabelas de dimensões às vezes são chamadas de “alma” do data warehouse porque contêm os pontos de entrada e rótulos descritivos que permitem que o sistema DW/BI seja aproveitado para análise de negócios.”
fonte: https://www.kimballgroup.com/data-warehouse-business-intelligence-resources/kimball-techniques/dimensional-modeling-techniques/dimensions-for-context/
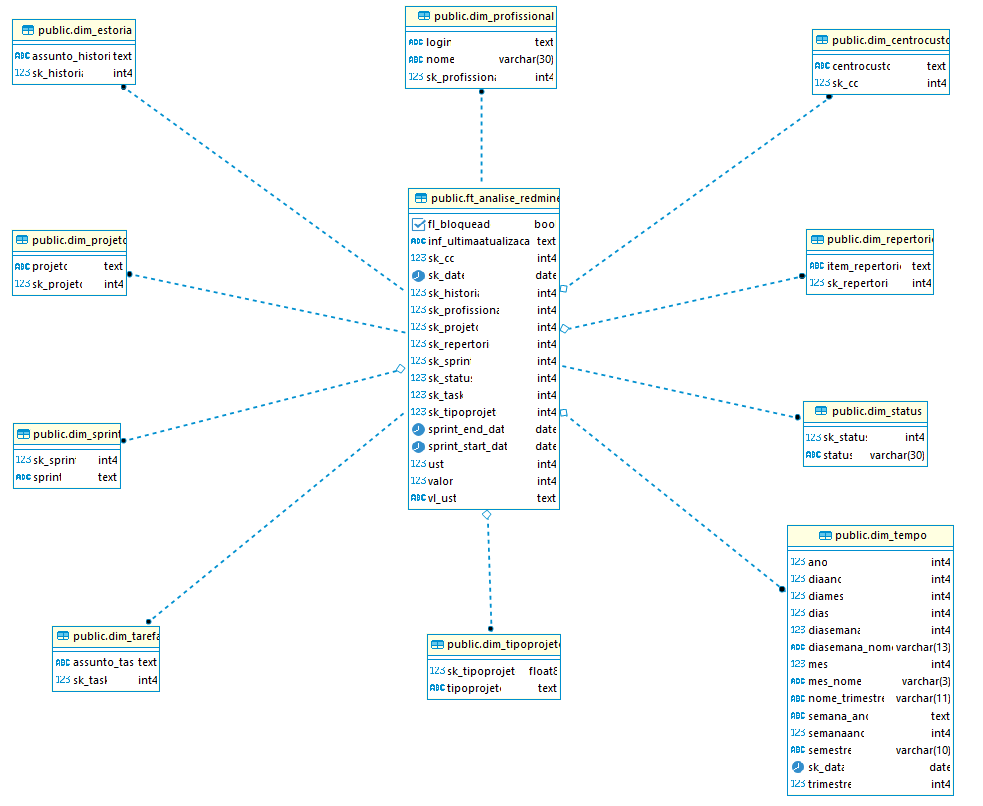
[Imagem_08]
* Ferramenta usada dbeaver.
* O exemplo de como ficou está modelagem dos dados, segundo o projeto
Sobre padrões de nomenclatura, qual a correta? Já visualizei casos de existir na própria documentação do projeto, ou na descrição da tabela.
Eu costumo deixar um Glossário na documentação para manter um padrão… por exemplo

Ou
COMMENT ON COLUMN <tabela>.<coluna> IS ‘<comentário>’;
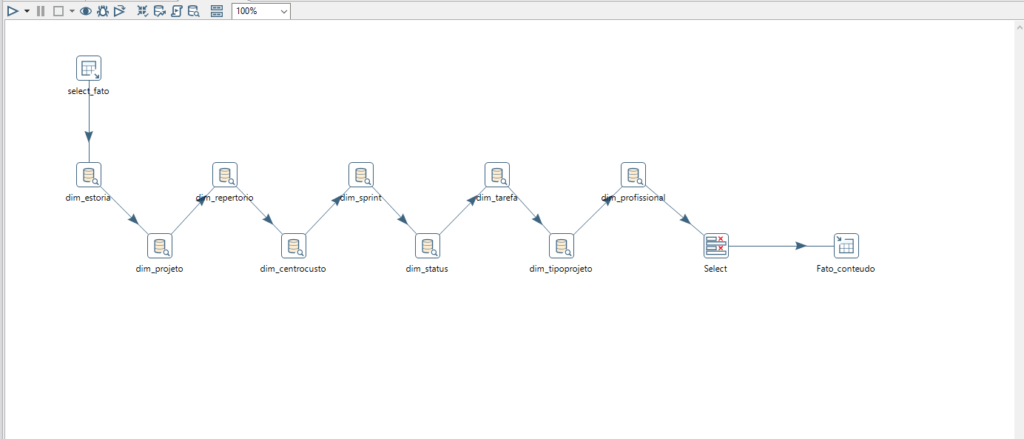
[figura_07]
* Ferramenta usada Pentaho Data Integration, carga da tabela Fato.
O processo de criação de um Data Warehouse não vejo que seja necessário explanar muito por esta bem no cotidiano, e depois que se faz a modelagem já temos avançado bastante.
Comecei a postagem discutindo os componentes que considero essenciais para o processamento de dados, enfatizando que a plataforma de nuvem e a ferramenta ETL escolhida são opcionais. O objetivo é criar uma linha de dados confiável que forneça os recursos para lidar com os dados à medida que chegam.
O pipeline de dados é o principal componente por trás do armazenamento de dados, por isso é importante estar ciente das diferentes opções que você tem ao construir caminhos para armazenar/tratar as informações sejam vindos de um Excel, txt ou um banco de dados
O mercado oferece uma ampla variedade de fontes de dados.
Resumi apenas que existe recursos que permitem diferentes formas de tratamento, assim como simplifiquei a criação de um Data Lake.

Não deixe que o título ou mesmo a capa o assustem; se você entender a ideia fundamental, certamente poderá se ajustar a novas práticas ou tendências.
Sobre novas postagens ou continuidade, existem muita coisa para falar, espero conseguir postar.
Entre eles podem ser
– Fermentas de orquestração do pipeline de dados (Ex Jenkins);
– Analise de performance de cargas e custos de armazenamento;
– Ferramentas de ETL;
– Encaixando a linguagem python no tratamento dos dados;
– Práticas de segurança de dados;
– Outras Plataformas de Nuvem;
– OLAP (um verdadeiro self service BI sem drag-drop);
– Maneiras de documentação.
. . . .
